Load Balancing: Comparative Architectures
HAProxy, Nginx, L4/L7 trade-offs, failure modes, and production patterns.

I help US & EU engineering teams build predictable, high-availability production infrastructure — without firefighting, hidden bottlenecks, or scaling surprises.
I specialize in PostgreSQL High Availability, Kubernetes at scale, and bare-metal performance engineering, with deep focus on uptime, latency, observability, and security.
My work directly improves:
If you're looking to hire a senior DevOps engineer remotely, need a Kubernetes consultant for scale, or a PostgreSQL high availability expert, I start with a 30-minute infrastructure audit and deliver a concrete improvement plan.
Lead offer: 30-minute DevOps audit → you receive a prioritized action plan for reliability, security, and cost.
Stable deployments, incident readiness, compliance evidence, and full CI/CD-to-runtime ownership.
Architectures that handle high RPS with predictable latency and resilience under failures.
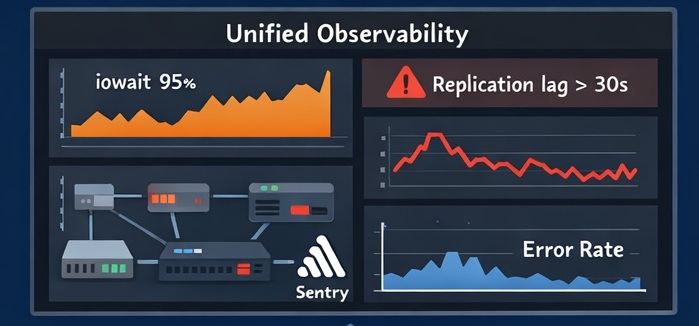
Metrics, logs, traces, and alerting for fast MTTR (Prometheus/VictoriaMetrics, Grafana, ELK, Sentry).
Right-sizing, workload analysis, and infra decisions that reduce spend without sacrificing reliability.
Network segmentation, centralized SSO (Keycloak), access auditing, secrets management, least privilege.
Architecture diagrams, runbooks, recovery procedures, postmortems, and clear ownership boundaries.

HAProxy, Nginx, L4/L7 trade-offs, failure modes, and production patterns.
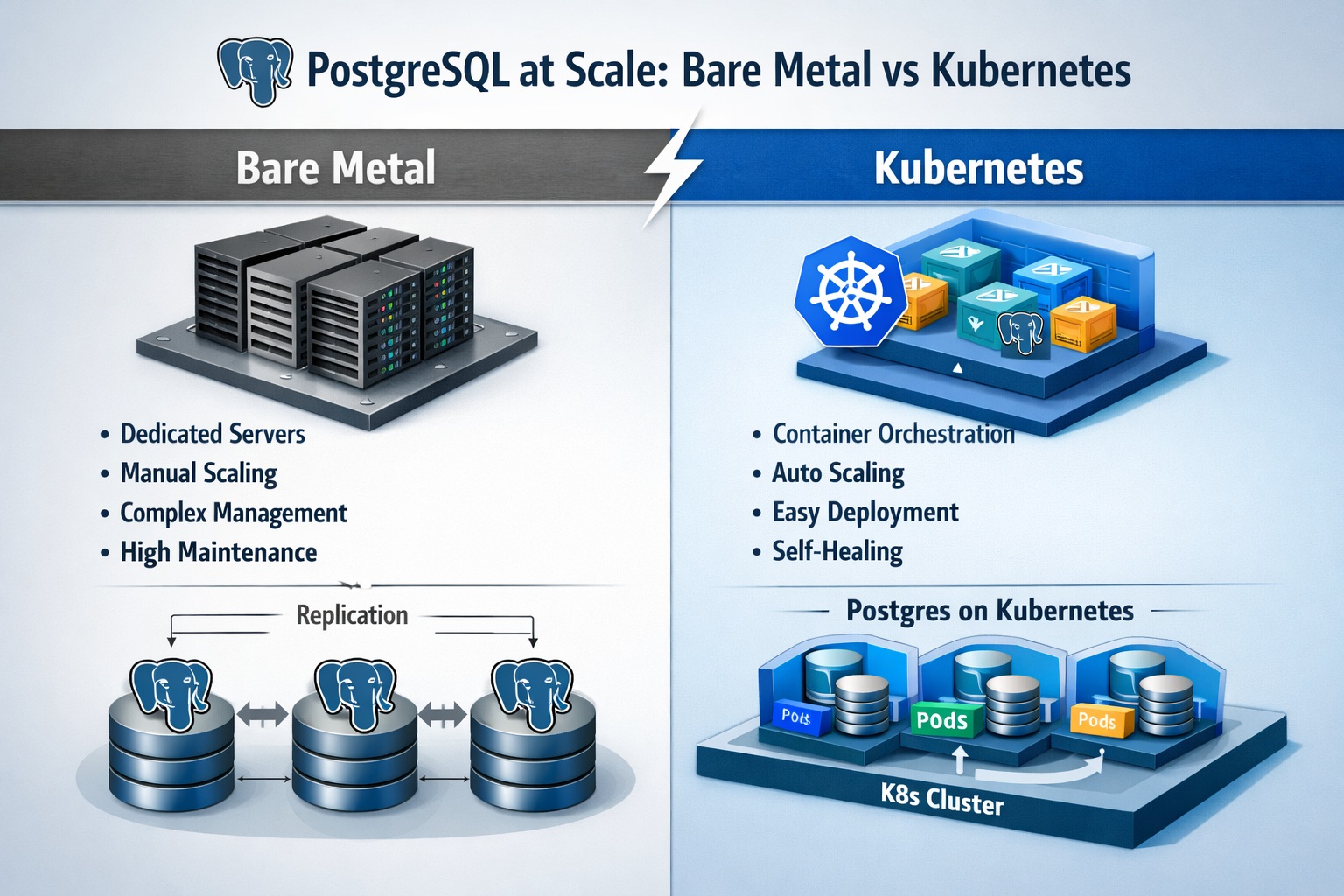
Bare Metal vs Kubernetes: latency variance, I/O predictability, failover, and cost.
When outsourcing DevOps makes strategic sense for startups and scale-ups.

Seamless updates in microservice environments with safe rollback.

Zero Trust security, Keycloak SSO, access auditing, Vault secrets, and audit-ready change control.

Lessons from the field: performance, control, and predictable costs.

How we reduced spending without sacrificing performance and reliability.
Clear outcomes, predictable process, and measurable reliability improvements. If you’re not sure where to start — pick the Audit Sprint.
30–60 minutes call + quick infra review → actionable plan.
Hands-on improvements with observability & safer releases.
Full-stack production reliability: uptime, latency, security, delivery.
Mission-critical systems with strict uptime expectations.
Reach out if you're looking for a reliable DevOps/SRE engineer for scalable, stable, and secure production systems.